Week 4
| Class | C4W4 |
|---|---|
| Created | |
| Materials | |
| Property | |
| Reviewed | |
| Type |
Special applications: Face recognition & Neural style transfer
What is face recognition?
In the face recognition literature, people often talk about face verification and face recognition.

Verification
- Given an input image as wellas a name or ID of that person the job of the system is to verify whether or not the input image if that of the claimed person. (one-to-one problem)
Recogniton
- This is much harder than the verification, suppose K=100 in a recognition system database. If you apply this system to a recognition task with a 100 people in the database, you now have 100x chances of making errors
One Shot Learning
One of the challenges of face recognition is that you need to solve the one-shot learning meaning you need to be able to recognize a person given a single frame/image of a face.
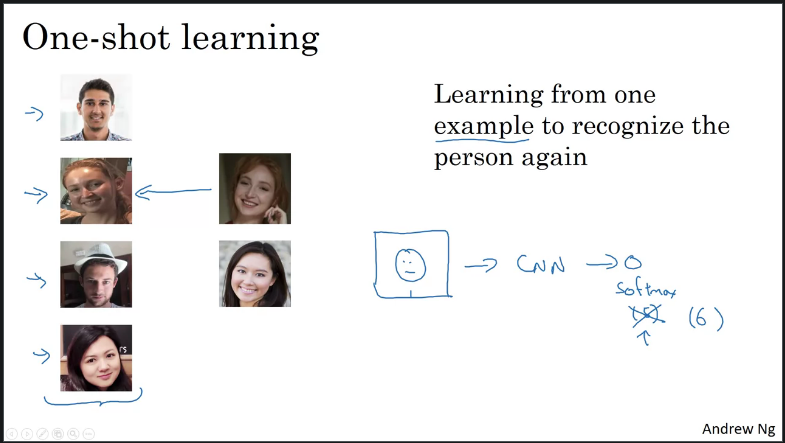
Suppose you have a database of 4 pictors of employeers in your organization. If someone shows up at the office we want them to be let in through the turnstile. What our system should do despite ever having seen only one image of person X it should recognize that that is th same person, and if the person isn't in the database it should recognize that.
One shot learning is learning from only one example to recognize the person again.
One approach to try is to input the persons face into a ConvNet and output softmax output corresponding to number of inpu. However, this does not work as to what happens when a new person joins the organization - Will you retrain the ConvNet?
Instead you want to have a ConvNet that would learn similarities through a function .

This function takes in 2 input images and outputs the free of difference between them. If the 2 images are of the same person then the output will be a small number vice-versa. During recognition, if the degree of difference between them is less than some hyperparamete threshold then you ould predict that these 2 pictures are the same person vice-versa.
This is how you address the face verification problem. To use this for face recognition, given a new picture you would use the function to compare the 2 images then compare the output with the images stored in the database. By doing one shot learning, you never have to train your ConvNet everytime someone new joins the organization.
Siamese Network
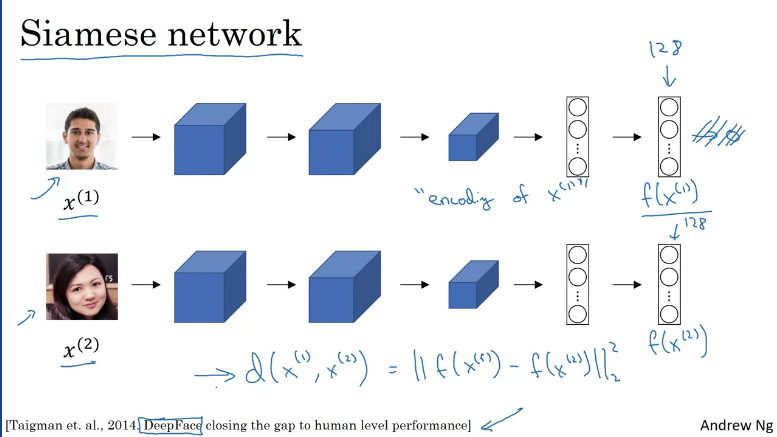
The function d introduced in the one shot learning section which takes in 2 input faces and output the similarities, can be improved using Siamese network.
Suppose you have an input image which goes through a sequence of conv, pooling and fc layers to end up with a 128 feature vector encoding of the input before being fed to a softmax which is omitted.
The way face recognition is built is by comparing 2 pictures (suppose input picture and ), these pictures are fed into the same neural network with the same parameters and get different feature vector of 128 numbers which encodes the 2nd picture. The encoding for the 2nd picture will be . Finally define the image of distance between and as the norm of the difference between the encodings of these 2 images, this is called a Siamese neural network.
How to train a Siamese network.
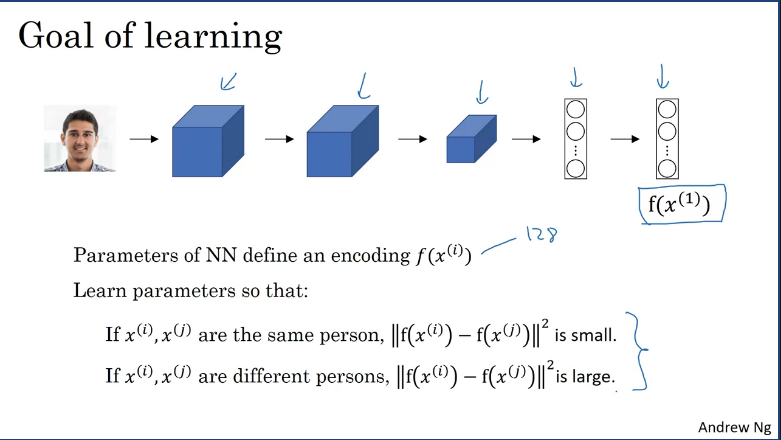
- Given an input image , the neural network outputs a 128 dimentional encoding
- You would need to learn parameters, so that: if 2 pictures of the same person then the distance between their encodings should be small and in contrast, if their not the same the distance should be large.
Triplet Loss
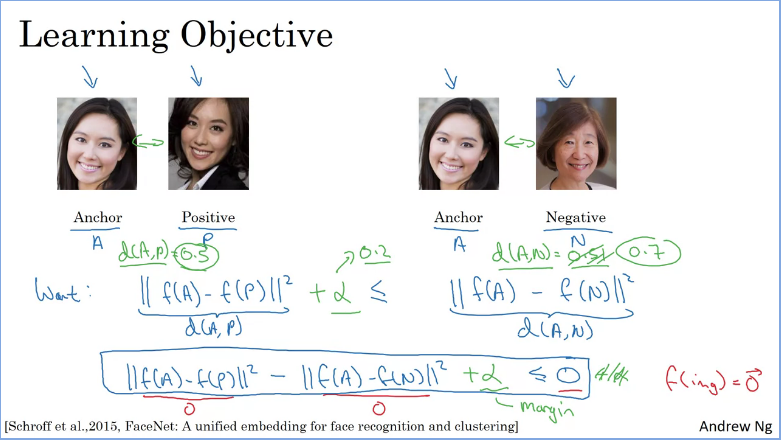
One way to learn the parameters of the neural network so that it gives you a good encoding for your pictures of faces is to define an applied gradient descent on the triplet loss function.
According to https://machinelearning.wtf/terms/triplet-loss/, The triplet loss is a loss function that come from the paper FaceNet: A Unified Embedding for Face Recognition and Clustering. The loss function is designed to optimize a neural network that produces embeddings used for comparison.
In order to apply triplet loss, you need to compare pairs of images. Suppose you have an input picture (captioned Anchor) in order to learn the parameters of the neural network you have to compare it with several other pictures at the same time.
For example, given a pair of images (on the left) the encordings should be similar because theyre the same person, whereas the other pairs (on the right) encodings should be different sinces those are different people.
To do this the triplet loss function looks at one anchor images and then calculates the distance between the anchor and the positive image (another picture of the same person), whereas when comparing the achor image and the negative image the distance should be further apart sinces theyre different people. According to the triplet loss you will always be looking at 3 images at a time.
So what you want is for the parameters of your neural network of your encodings to have the following properties:
- Encoding between anchor and positive be less or equal to encoding between anchor and negative. i.e
To prevent the neural network outputing zero for all encordings if , we need to modify the formula such that it doesn't need to be just less than or equal to 0, but needs to be quite a bit smaller than 0. i.e. we need this to be less than negative alpha where is a margin hyperparameter which prevents this neural network from outputiing trivial solutions.
The margin , ensures that the anchor positive pair and anchor negative pair are pushed further away from each other making sure than
How the triplet loss function is defined.

The triplet loss function is defined on triples of images. So, given 3 images A, P, N. The positive examples being the same person as the achor and negative being different, the loss is defined as the formula shown above.
If you have a training set of 10k pictures with 1k different persons, what you would need to do is take the 10k pictures and use them to generate and select A,P,N triplets and then train your algorithm using gradient descent on the cost function. The purpose of training your system is that you need a dataset where you have multiple pictures of the same person at least for some people in the training set so that you have pairs of anchor and positive images.
How to choose the triplets?

Given 2 randomly chosen images of people chances are A and N are much different than A and P, so the neural network won't learn much from them. To solve this you would need to choose triplets A,P and N that are hard to train on so that the containt for all triplets be satisfied. The benefits of choosing these triplets yourself improves the learning algorithm as compare to randomly choosing them as the gradient descent won't be able to do anything because the neural network will always get them right all the time. It's only by using hard triplets that the gradient descent precedure has to do some work to try to push these distances further away from each other. More details can be found in the paper.
How to train on triplet loss?

In order to train on triplet loss, you need to take your training set and map it to a lot of triples as shown in the image above, where theres a triple with an anchor and a positve both for the same person and the negative of a different person and so no. After defining your training sets of anchor positive and negative triples is to use gradient descent in order to try to minimize the cost function as defined in previous section, that will have the effect of that propagiting to all of the parameters of the neural network in order to learn an encoding so that the distance of 2 images will be small when those 2 images are of the same person and large when persons are different.
Face Verification and Binary Classification
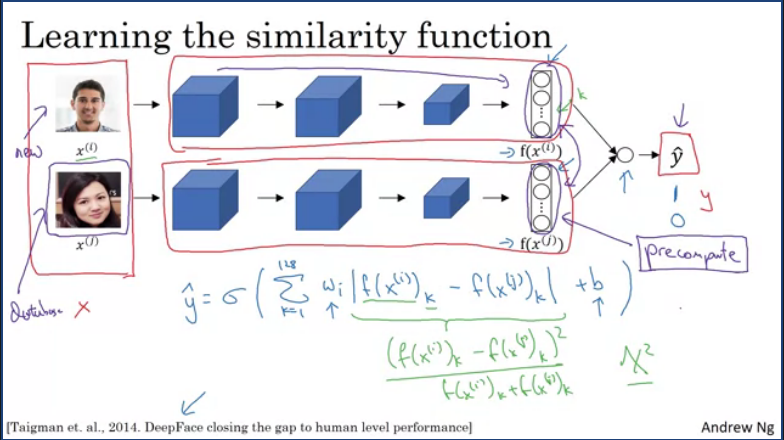
Another way of doing facial recognition is through binary classification, by taking a pair of input image through individual siamese neural networks(parameters on both networks are the same) and have both of them compute the 128d embeddings and these will be input to a logistic regression unit in order to make predictions. Where the target output will be 1 if both images are of the same person or 0 if different.
The output y hat will be a sigmoid function, applied to some set of features feeding in, these then compute the differences between the encodings.
Instead of having to compute input everytime, one would have the embeddings saved in the database (as you do not need to store raw images of faces in the database) and only run input through the siamese network thus improving perfomance to make predictions.
What is neural style transfer?

Suppose you have an image (Content) and want to recreate it with another image (style) in order to get an output image which combines the 2 as a generated image and in order to implement thais you would need to look at the features extracted by ConvNet at various layers. This is known as neural sytle transfer and it allows you generate new images but repainted based on the style of another image.
What are deep ConvNets learning?
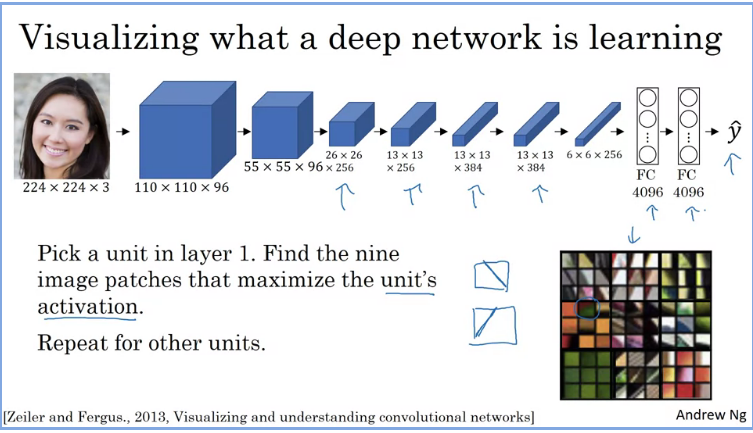
Suppose you have an input image fed to a trained ConvNet similar to an AlexNet and you want to visualize what the hidden units in different layers are computing.
You would need to start/pick with a hidden unit suppose in layer 1 and you have scanned through your training sets in order to find an image that would maximize that layers/unit activation, in other words pause your training set through your neural network and figure out what image that maximizes that particular unit's activation. If you would plot the activated unit's activation you would find nine input images that look like the 3x3 images on the top left. The neural network is looking for edges at that stage as illustrated in the drawing with a diagonal strikethrough. When those images that maximize that layers activation are found you move to the next one and repeat for other layers/units in order to find other neural network representations.
This gives one a sense that trained hidden units in layer 1 are often looking for relatively simple features such as edge or a particular shade of color.
How about in the deeper layers, what is the neural network learning?

In later and deeper layers that neural network will see a larger region of the image, where at extreme end each pixel could hypothetically affect the output of these later layers of the network. When this procedure is repeated over and over you would see the visualization as shown in the image above where at each layer the neural network learns different aspects of the image. Layer 2 shows a 3x3 grid (9 patches) which causes that one hidden unit to be highly activated and then each grouping of 9 image patches causes that hidden unit to have a very large output thus a very large activation. This is repeated for all hidden layers.
- Layer 1

This is activated when the input images contains edges and certain angles.
- Layer 2

This layer detects more complex patterns, shapes and textures, where certain hidden units looks for vertical lines and different shapes.
- Layer 3

This looks like it responds to rounder shapes in the lower left hand portion of the image.
- Layer 4

This layer seems to have started classifying images and detecting various things in the input images
- Layer 5

This layer is detecting sophisticated things, from flowers and dogs.
Cost Function
To build a Neural Style Transfer system, You define a cost function for the generated image. And the objective is to minimize that cost function such that you can generate the image that you want.
The problem formunation is that you're given a contant image , a style image and your goal is to generate a new image . In order to implement neural style transfer you need to define a cost function that measures how good is a particular generated image and we'll use gradient descent to minimize in order to generate this image.
In order to check how good a particular image is, we define cost function in 2 parts.
- The first part is the content cost, which measures how similar is the contents of the generated image to the content of the conted image :, described in the following section.
- This is then added to a style cost function which measures how similar is the style of the image G to the style of image S:
Finally these functions are then weighted with 2 hyperparameters and , one hyperparameter should be fine however the original authors used 2 different hyper parameters.

How does the algorithm work?
Having to find the cost function in order to actually generate new images what you do is descibed in the image below.

Suppose you start with the content images and stye image, then when G is randomly initialized this would results in a white noise based image where each pixels value is random. As you run gradient descent, you iteratively minimize the cost function slowly through the pixel value as shown on the images on the right and this would result in your content image rendered in the style of your style image.
Content Cost Function

- Suppose you use hidden layer to compute the content cost . If is a very small number when hidden layer 1 is used, then this will force your generated image to pixel values very similar to your content image. Whereas, if you use a very deep layer, then it's just asking, "Well, if there is a dog in your content image, then make sure there is a dog somewhere in your generated image." In practice layer is neither too shallow or deep in the network.
- Using a pre-trained ConvNet, measure the similarities between a content image and a generated image.
(Element-wise squared differences)
Style Cost Function

Suppose you have an input image and compute features on different layers. Assume you choose some layer (arrowed) and maybe that layer defines the measure of the style of the image. What we would need to do is to define the style as the correlation between activations accross different channels() in the layer activation.
In order to compute the correlation between the different channels, for example looking at the lower right hand cordner you have some activatin in the 1st channel and some activation in the 2nd channel thus giving a part of numbers and then what you do is continue looking at different positions across this block of activations and look for paurs across the 2 channels.

Suppose the 1st (red) channel corresponds to the top-mid neuron highlighted which seems like its trying to figure out if there;s vertical texturs in a particular position in the and suppose the 2nd (yellow) channel corresponds to the left-mid neuron highlighted which is vaguely looking for orange colored patches. What it means for the 2 channels to be highly correlated is that which ever part of the image which contains this type of subtle vertical texture that part will probably not have that orange-ish tint. So the correlation tells us which of these high level texture components tend to occur or not occur together in part of an image and that's the degree of correlation that gives us a way of measuring how often these different high level features occur together and don't occur in different parts of the image.
Given an image compute the style matrix, which measures channel correlations.

The style matrix computes which measures the correlation between and . The computation of style matrix is done for both the style and generated images.
Corrected formula is:

The style cost function formula is the squared difference:
instead of just the difference:
The style cost function is:
What this fomular does is it allows the to use different layers in a neural network which measures relatively simpler low level features like edges as well as some later layers which measure high level features which then causes a neural network to take both low level and high level correlations into account when computing style.
By computing the cost function you can generate good looking neural artistic and novel artwork.
1D and 3D Generalizations of models
It turns out that the applications done to 2D data can also be applied to 1D and 3D data. In the previous lessons we saw how a 2D input image can be convolved to a simple
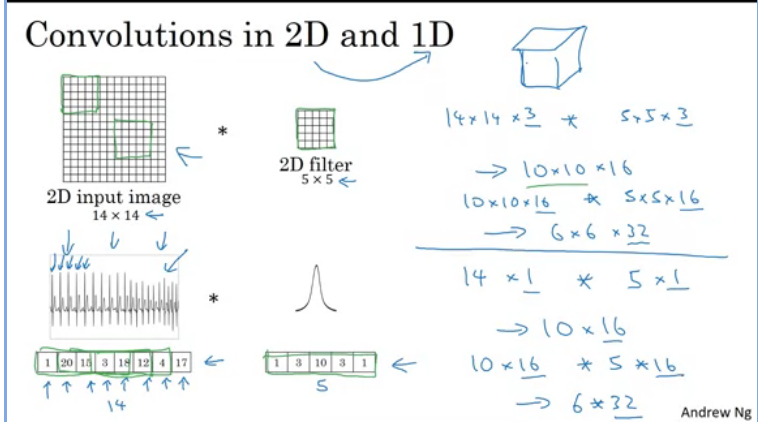
From the image above a 1D input images is convoled to a 1D filter similar to what we did to a 2D image. However, for 1D data we ususally use R-CNNs instead of ConvNets
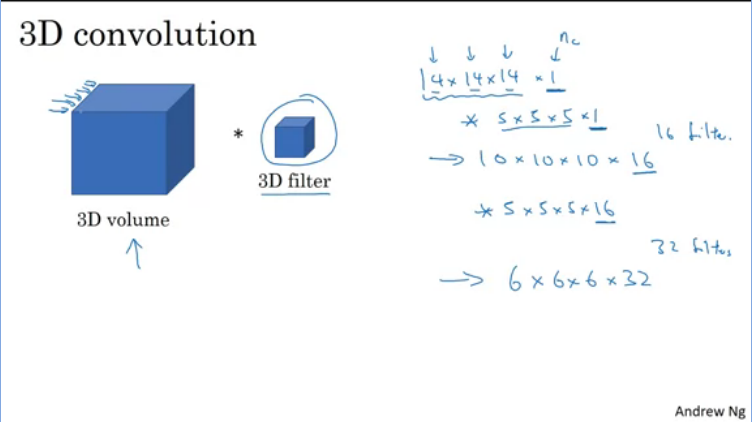
3D data is also calculated in a similar manner however, in this case you have where D is the depth.
Q & A
Special applications: Face recognition & Neural style transfer
- Face verification requires comparing a new picture against one person’s face, whereas face recognition requires comparing a new picture against K person’s faces.
- True
- Why do we learn a function for face verification? (Select all that apply.)
- This allows us to learn to recognize a new person given just a single image of that person.
- We need to solve a one-shot learning problem.
- In order to train the parameters of a face recognition system, it would be reasonable to use a training set comprising 100,000 pictures of 100,000 different persons.
- False
- Which of the following is a correct definition of the triplet loss? Consider that . (We encourage you to figure out the answer from first principles, rather than just refer to the lecture.)
-
- Consider the following Siamese network architecture:
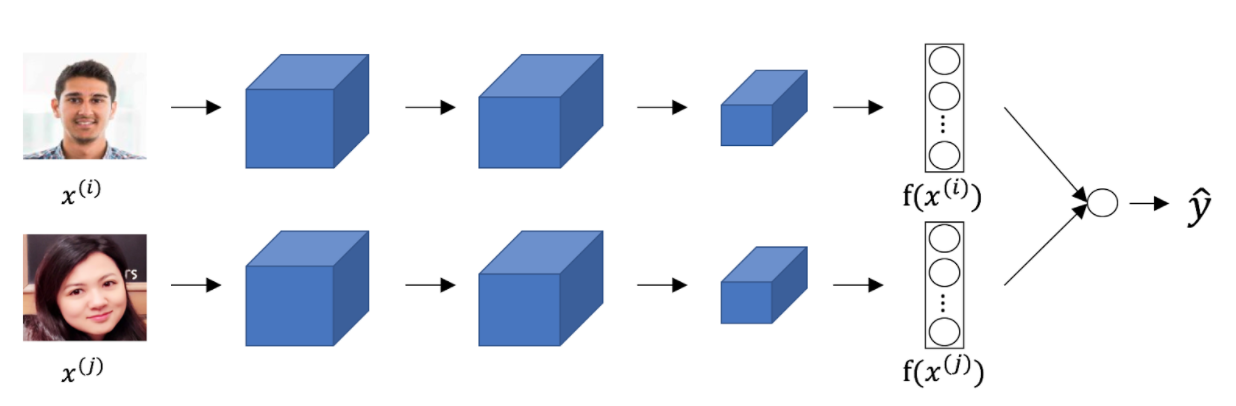
The upper and lower neural networks have different input images, but have exactly the same parameters.
- True
- You train a ConvNet on a dataset with 100 different classes. You wonder if you can find a hidden unit which responds strongly to pictures of cats. (I.e., a neuron so that, of all the input/training images that strongly activate that neuron, the majority are cat pictures.) You are more likely to find this unit in layer 4 of the network than in layer 1.
- True
- Neural style transfer is trained as a supervised learning task in which the goal is to input two images (), and train a network to output a new, synthesized image ().
- False
- In the deeper layers of a ConvNet, each channel corresponds to a different feature detector. The style matrix measures the degree to which the activations of different feature detectors in layer ll vary (or correlate) together with each other.
- True
- In neural style transfer, what is updated in each iteration of the optimization algorithm?
- The pixel values of the generated image
- You are working with 3D data. You are building a network layer whose input volume has size 32x32x32x16 (this volume has 16 channels), and applies convolutions with 32 filters of dimension 3x3x3 (no padding, stride 1). What is the resulting output volume?
- 30x30x30x32