Week 3
| Class | C4W3 |
|---|---|
| Created | |
| Materials | |
| Property | |
| Reviewed | |
| Type |
Detection algorithms
Object Localization
In simple term object classification with localization means that not only does it label an object but the algorithm also is responsible for placing a bounding box around the object of interest.
Where localization refers to figuring out where in the picture the object detected is?
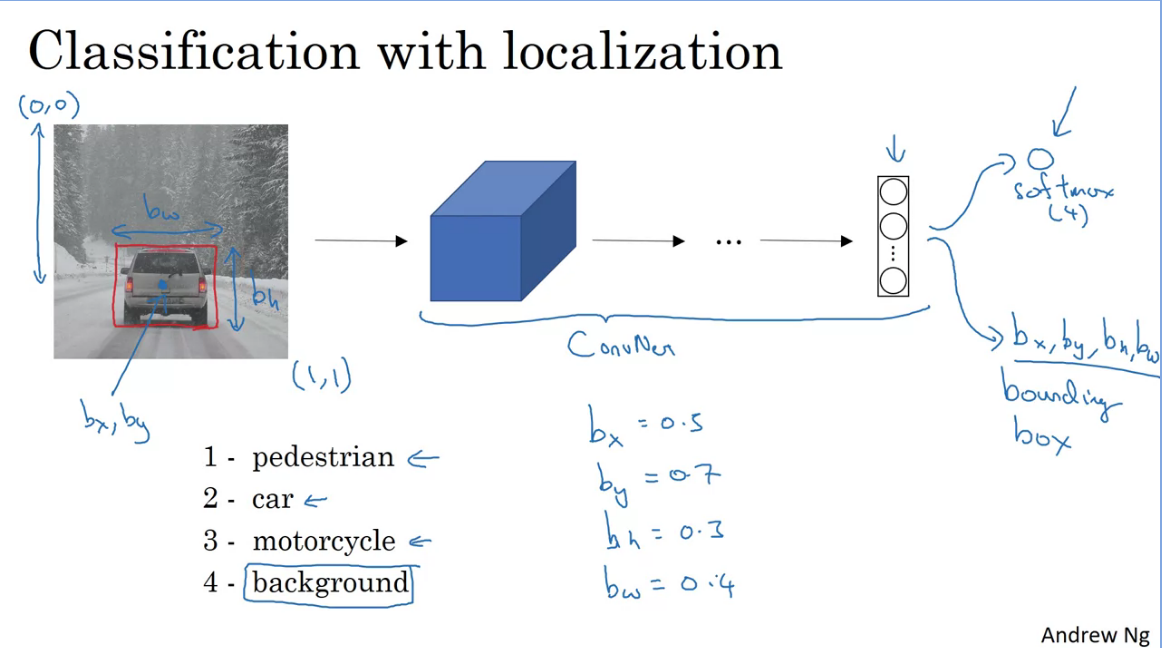
Suppose you are building a self driving car application which takes in an image input and outputs (with softmax) various classified labels on the output using ConvNets - This is a standard classification pipeline.
How about if you would want to localize the car in the image as well, in order to do that you would need to change your nn to have few more output units that would also output coordinates to a bounding box.
The new nn could also output additional params for the bounding box ()
Given an input, this is how you would define the target label
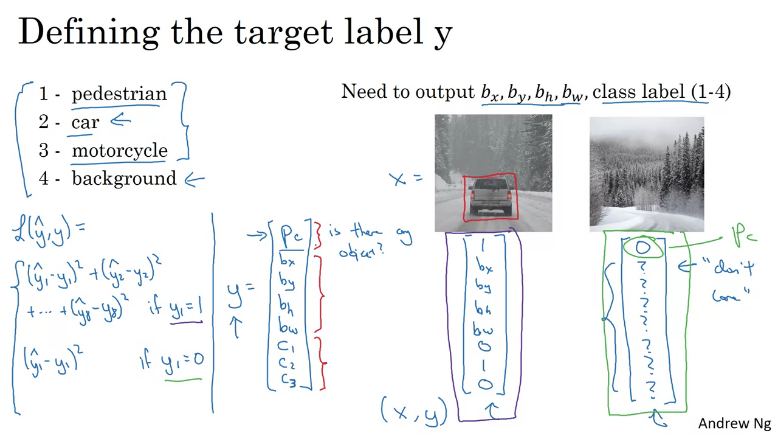
Note: , where is the probability that there's an object. If no object is detected else
Determine loss:
- In order to determine (class labels) loss you could use a log-like feature loss to the softmax output.
- For the bounding box coordinates you could use squared error and,
- For you could use logistic regression loss.
Landmark Detection
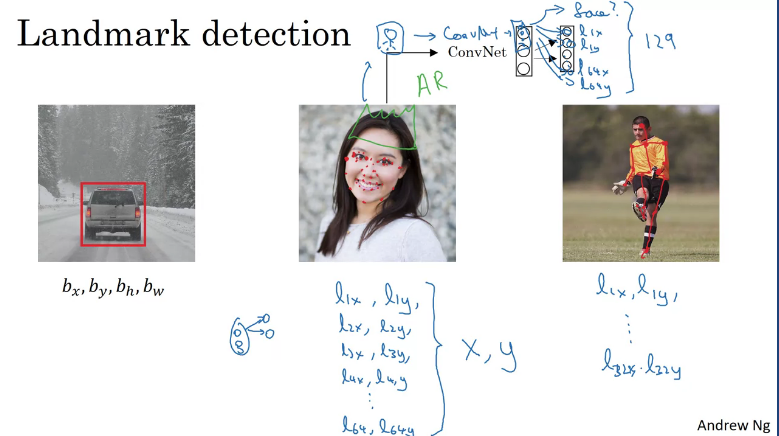
Suppose you are building a face recognition application, and you want your algorithm to tell you where's the corner of someones eye coordinates .
In order for the nn to detect those features you could label them and so on for the different points on the persons face.
To achieve that you would input an image of a face into a ConvNet which would output 129 output (1 detects if face, 64x and 64y landmark points) units. This is similar to how you would determine estimated pose of a person.
Object Detection

Suppose you want to build a car detection algorithm. First you would need a label training set (x, y) with closely cropped examples of cars where x input is just an image of a car. Given the label training set you can train a ConvNet that inputs an image and outputs if it is a car or not.
Once the ConvNet has been trained it could be used in Sliding Windows Detection. In Sliding Windows Detection you start by picking a certain window size, shown in the image below. Then you would input into this ConvNet a small rectangular region and have the ConvNet detect if there's a car this will have to be fed and slide the window accross the whole image while incremenntly increasing the window size and sliding (with some stride) it over the entire images which the hope that so long that theres a car in the image the ConvNet would detect if there's a car.

If you use a very large stride or step size then this reduces the number of windows to pass through the ConvNet but a coarse granuality may hurt the perfomance. Whereas if you use a small stride/step size this would cause high computational cost.
Running a single ConvNet classification task is much more expensive when using Sliding Window Detection and it's infeasibly slow, unless you use a very fine granuality or small stride you might end up not able to localize the objects accurately within the image.
Unless Sliding Window Detection is implemented convolutionally.
Convolutional Implementation of Sliding Windows
In the previous section, we were introduced to the Sliding Window detection algorithm using a ConvNet which was too slow, in this section we will implement the algorithm convolutionally to improve perfomance.
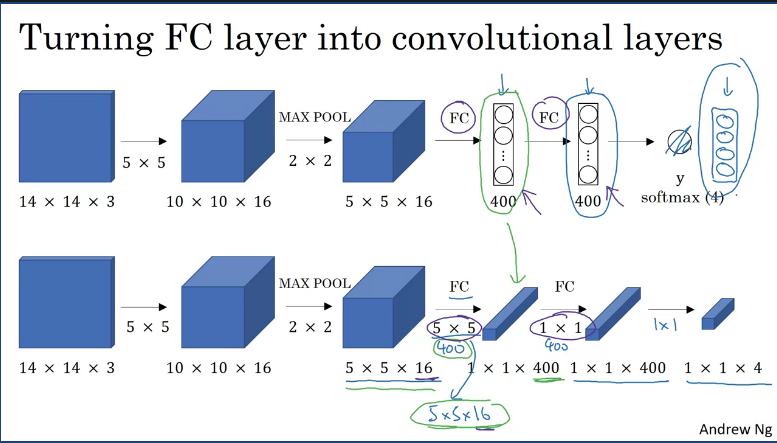
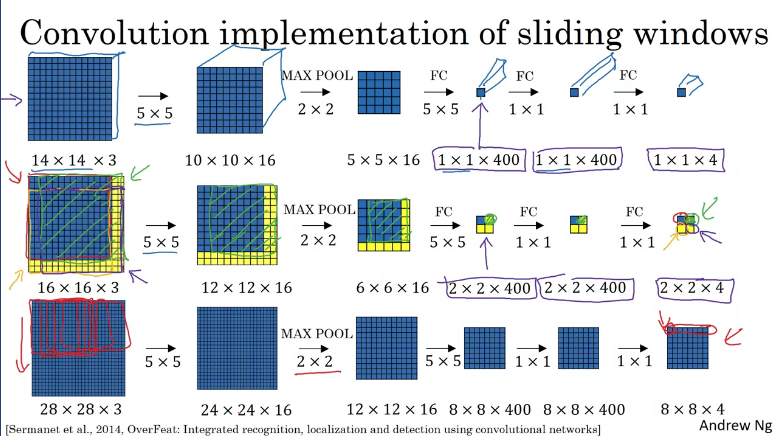
Suppose you detection algorithm inputs 14x4x3 image then uses a 5x5 filters, and it uses 16 of them to map it from 14x14x3 to 10x10x16. And then does a 2x2 max pooling to reduce the height and width to 5x5x16. Then a fully connected layer to connect to 400 units. Then another fully connected layer and finally outputs a Y using a softmax unit (Y will be 4 numbers, corresponding to the class probabilities of the 4 classes that softmax units is classified amongst These classes could be pedestrian, car, motorcycle, and background or something else.
Now in order to turn the network into a complete ConvNet you would need to convert the fully connected layer by implementing a 5x5 filter and let's use 400 5x5 filters. So if you take a 5x5x16 image and convolve it with a 5x5 filter, remember, a 5x5 filter is implemented as 5x5x16 because our convention is that the filter looks across all 16 channels. So the 16 and this 16 must match such that the outputs will be 1x1. And if you have 400 of these 5x5x16 filters, then the output dimension is going to be 1x1x400. So rather than viewing these 400 as just a set of nodes, we're going to view this as a 1x1x400 volume. Mathematically, this is the same as a fully connected layer because each of these 400 nodes has a filter of dimension 5x5x16. So each of those 400 values is some arbitrary linear function of these 5x5x16 activations from the previous layer. Next, to implement the next convolutional layer, we're going to implement a 1x1 convolution. If you have 400 1x1 filters then, with 400 filters the next layer will again be 1x1 by 400. So that gives you this next fully connected layer. And then finally, we're going to have another 1x1 filter, followed by a softmax activation. So as to give a 1x1x4 volume to take the place of these four numbers that the network was operating. So this shows how you can take these fully connected layers and implement them using convolutional layers so that these sets of units instead are not implemented as 1x1x400 and 1x1x4 volumes.
Convolution implementation of slidin windows
In the original sliding windows algorithm, you might want to input a test image as the blue region into a ConvNet and run that once to generate a classification 0/1 and then slide it down a bit, suppose you use a stride of 2 pixels and then slide that to the right by 2 pixels to input this green rectangle into the ConvNet and we run the whole ConvNet and get another label 0/1. Turns out a lot of this computation done by these ConvNet is highly duplicative, so what the convolutional implementation of sliding windows does is it allows these asses in the ConvNet to share a lot of computation.
What this convolution implementation does is, instead of forcing you to run foward propagation on 4 subsets of the input image independently, Instead, it combines all 4 into 1 form of computation and shares a lot of the computation in the regions of image that are common.
Convolution implementation of sliding windows on an image
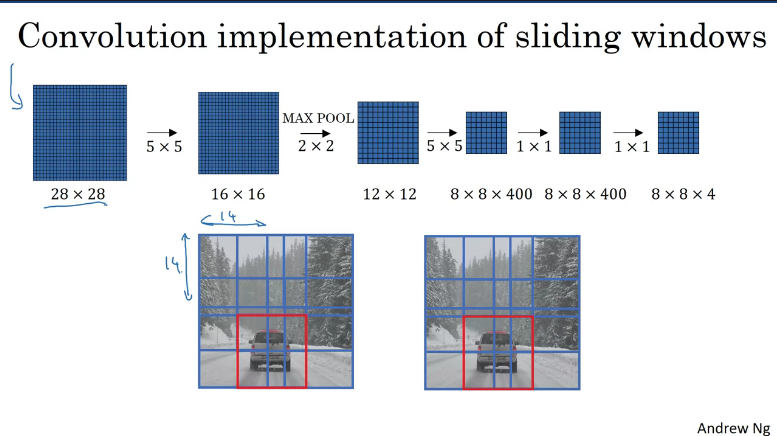
Summarise, to implement sliding windows, previously, what you do is you crop out a region. Let's say this is 14x14 and run that through your ConvNet and do that for the next region over, then do that for the next 14x14 region, then the next one, and so on, until hopefully that one recognizes the car.
But now, instead of doing it sequentially, with this convolutional implementation described above, you can implement an efficient sliding windon on an entire image, all maybe 28x28 and convolutionally make all the predictions at the same time by one forward pass through this big ConvNet and hopefully have it recognize the position of the car. However, this implementation has another weakness, which is to accurately determine the position of the bounding boxes.
Bounding Box Predictions
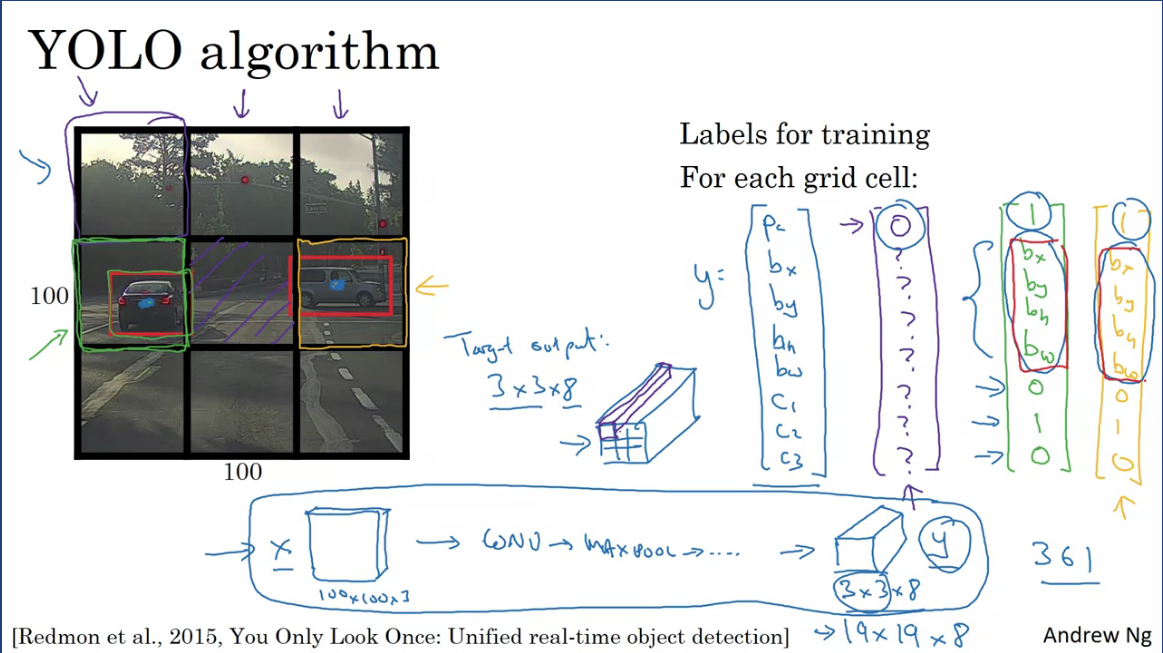
In order to get more accurate bounding box predictions using sliding windows, you would take 3 sets of locations and run the classifier through it. And in most cases the bbox doesn't match up perfectly with the position of the object. That's where the YOLO algorithm comes in, Suppose you have an input image 100x100 and place a 3x3 grid on the image, where the basic idea is to take the image classification and localization algorithm and apply that to each of the 9 grid cells of the image.
For each of the grid cells you specify a label Y, where the label Y is an 8 dim vector containing the probability, bbox coordinates and class labels for each predicted object. The output label Y would be the same for each grid cell and what the YOLO algorithm does is it takes the midpoint of each of the 2 objects and assigns the object to the grid cell containing the midpoint.
So the car on the left (green vector) and right(yellow vector) are both assigned individual grid cells and every other grid cells with no objects are don't cares (since prob → 0). So the target output volume will be 3x3x8 volume where 3x3 refers to the grid and 8 are the Y labels.
The advantage of this algorithm is that the nn outputs precise bounding boxes around the region of interest, at test time you would feed an image X and run forward propagation until you get an output Y, then for each of the 9 outputs of each 3x3 positions in the output you can read off the probability of each 3x3 containing an object (1 or 0). If there's an object, what object is it and where is the bounfing box for the object in that grid cell?
How to decode the bounding box coordinates?
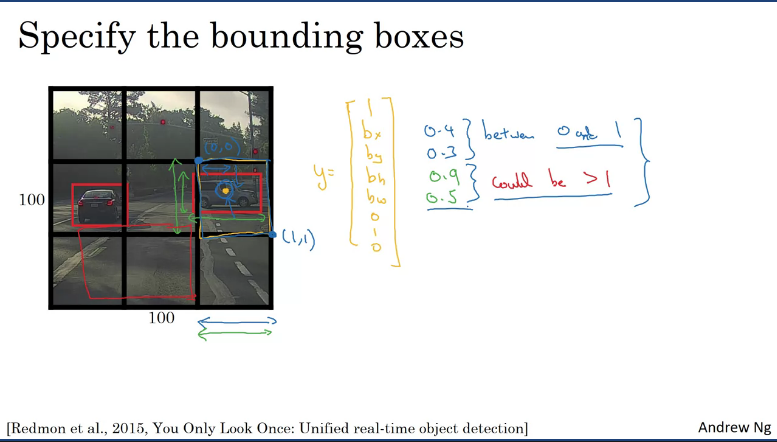
Given these 2 cars and looking at the car on the right from the 3x3 grid, the target label Y will be 1 since . In the YOLO algorithm, relative to the grid containing the car. The upper left point of the grid coordinates would be and lower right point . So to specify the position of the midpoint (orange dot):
- might be 0.4 to the right,
- 0.3 down,
- is specified as a fraction of the overall width of this box, so the width of the red box might be 90% of the blue line, so is 0.9
- is maybe one hald of the overral height of the grid cell, in that case it would be 0.5
In other words, are specified relative to the grid cell and and has to be between 0 and 1 as bounded by the grid. But and can be greater than 1.
Intersection Over Union
How do you evaluate if your object detection algorithm is working well?

What the IoU does is, it computes the intersection over union of these 2 bounding boxes, which the union is the area containing either boxes (shaded green), whereas the intersection is the smaller region (shaded orange).
If IoU is greater than 0.5 (thumbsuck) then the predicted bounding box is correct, this is one way to map localization of the object.
This is a simpler way of measuring how similar two boxes are to each other.
Non-max Suppression

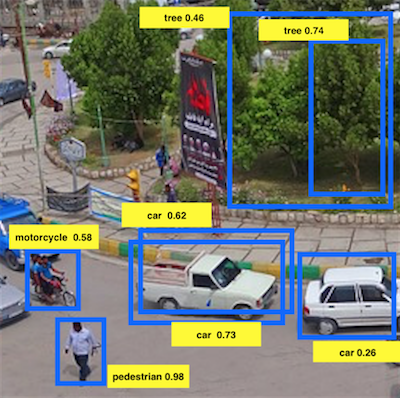
Suppose, you want to detect pedestrians, cars and motorcycles in this image above, You might place a 19x19 grid over it and while running classification and localization algorithm you might detect 2 cars on the image and place a midpoint on them for each grid point. But now how do you ensure you have detected a single car instead of multiple per grid?

What non-max suppression does, is it cleans these detections, such that you end up with just one detection per car rather than multiple detections per car. It evaluate the probabilities of the various detections and only takes the largest one. Then the non-max suppresion looks at all the remaining bbox with high overlap and IoU then suppreses them. The non-max suppresses probabilities will be the ones considered.
What non-max, means is that you're going to output your maximal probabilities classification but suppress the close-by ones that are non-maximal.
Implemeting non-max suppression

Anchor Boxes
One of the problems we've seen so far is that each of the grid cells can only detect a single object at a time. What if you want to detect multiple objects on a single grid?
According to https://d2l.ai/chapter_computer-vision/anchor.html, anchor boxes generates multiple bounding boxes with different sizes and aspect tatios while centering on each pixel.
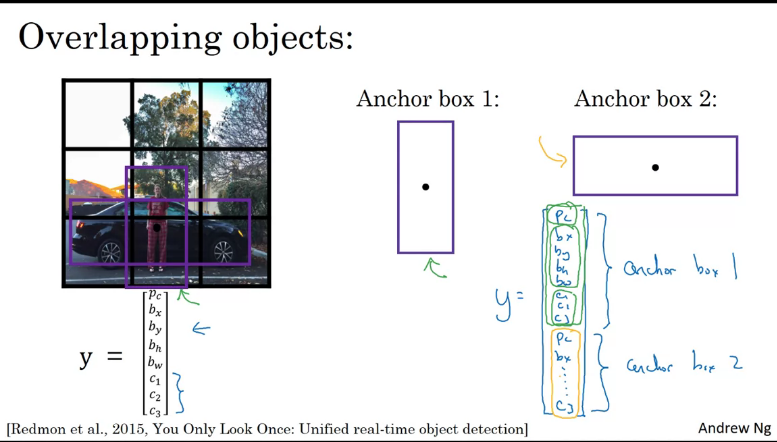
Suppose you have an image, with a 3x3 grid and notice that the midpoint of the pedestrican and the midpoint of the car are in almost the same place and both of them fall into the same grid cell. So, for the grid cell, if Y outputs a vector where you are detecting three classes, pedestrian, cars and motorcycle it won't be able to output 2 detections. However, with the idea of anchor boxes, what you end up doing is to pre-define 2 different shapes called anchor boxes or anchor box shapes. And be able to associate 2 predictions with 2 anchor boxes. So Y outputs will have 2x 8 outputs based on the number of anchor boxes.
Anchor box algorithm

Refer to: https://medium.com/@andersasac/anchor-boxes-the-key-to-quality-object-detection-ddf9d612d4f9
YOLO Algorithm
During training
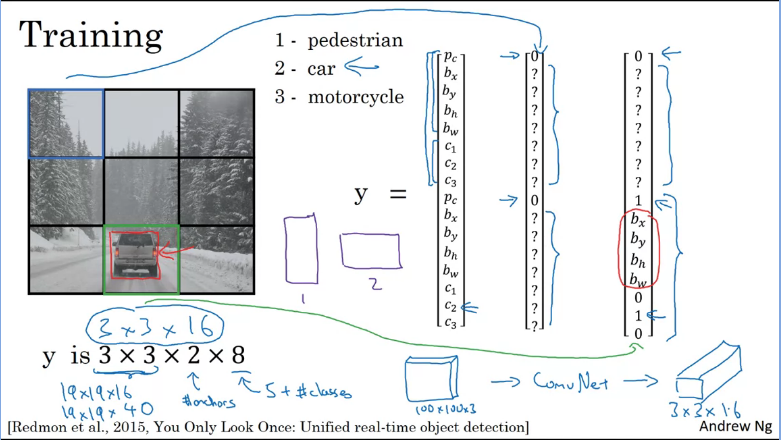
Suppose you're training an algorithm which takes in an image and detects if it contains any of the three objects: pedestrians, cars, and motorcycles. If you're using two anchor boxes, then the outputs will be 3x3 because you are using 3x3 (grid cell) x2 (anchor boxes) x8( values + number of classes). Which can be viewed as
Most of the grid cells have nothing in them, but for the bottom-mid cell you would have for anchor 2. Assuming anchor 1 is vertical(lenghthier) and anchor 2 is horizontal(wider).
Making Predictions
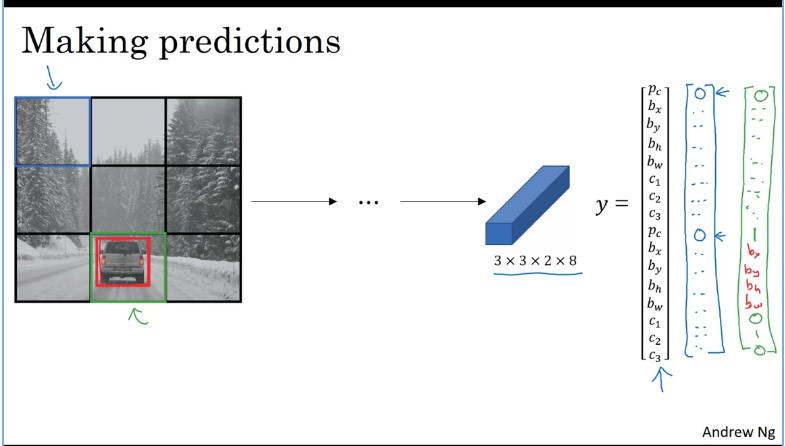
For the grid cells which contains nothing it would output random noise(values) with a , then finally you would run it through a non-max suppression.
Outputting the non-max suppressed outputs

Region Proposals: R-CNN

Regions with convolutional networks(R-CNN) tries to pick regions which makes sense to run your ConvNet classifier on, rather than sliding windows on every single window. You instead select just a few windows and run your ConvNet through them.
This is done by running a segmentation algorithm that would result in a segmantic output blob and run a classifier on it then determines if there's a region of interest then place the bounding box on it one at a time.
However, it turns out that this algorithm is a bit slow and over the years there's been improvements, but YOLO algorithm still a better alternative.

Q & A
- You are building a 3-class object classification and localization algorithm. The classes are: pedestrian (c=1), car (c=2), motorcycle (c=3). What would be the label for the following image? Recall

-
- Continuing from the previous problem, what should y be for the image below? Remember that “?” means “don’t care”, which means that the neural network loss function won’t care what the neural network gives for that component of the output. As before,

-
- You are working on a factory automation task. Your system will see a can of soft-drink coming down a conveyor belt, and you want it to take a picture and decide whether (i) there is a soft-drink can in the image, and if so (ii) its bounding box. Since the soft-drink can is round, the bounding box is always square, and the soft drink can always appears as the same size in the image. There is at most one soft drink can in each image. Here are some typical images in your training set:

What is the most appropriate set of output units for your neural network?
- Logistic unit,
- If you build a neural network that inputs a picture of a person’s face and outputs N landmarks on the face (assume the input image always contains exactly one face), how many output units will the network have?
- 2N
- When training one of the object detection systems described in lecture, you need a training set that contains many pictures of the object(s) you wish to detect. However, bounding boxes do not need to be provided in the training set, since the algorithm can learn to detect the objects by itself.
- False
- Suppose you are applying a sliding windows classifier (non-convolutional implementation). Increasing the stride would tend to increase accuracy, but decrease computational cost.
- False
- In the YOLO algorithm, at training time, only one cell ---the one containing the center/midpoint of an object--- is responsible for detecting this object.
- True
- What is the IoU between these two boxes? The upper-left box is 2x2, and the lower-right box is 2x3. The overlapping region is 1x1.
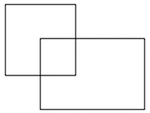
- 1/9
- Suppose you run non-max suppression on the predicted boxes above. The parameters you use for non-max suppression are that boxes with probability \leq≤ 0.4 are discarded, and the IoU threshold for deciding if two boxes overlap is 0.5. How many boxes will remain after non-max suppression?
- 5
- Suppose you are using YOLO on a 19x19 grid, on a detection problem with 20 classes, and with 5 anchor boxes. During training, for each image you will need to construct an output volume y as the target value for the neural network; this corresponds to the last layer of the neural network. (y may include some “?”, or “don’t cares”). What is the dimension of this output volume?
- 19x19x(5x25)