Week 3
| Class | C1W3 |
|---|---|
| Created | |
| Materials | https://www.coursera.org/learn/neural-networks-deep-learning/home/week/4 |
| Property | |
| Reviewed | |
| Type | Section |
Shallow Neural Network
Neural Networks Representation
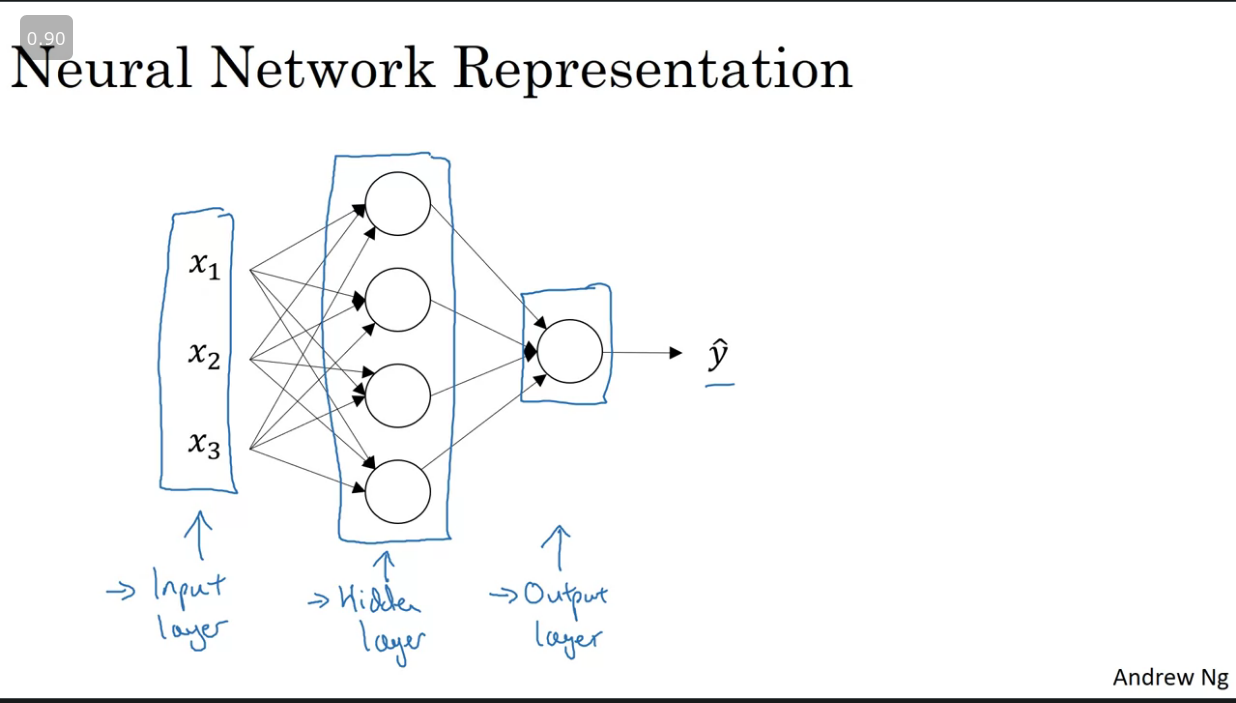
Below is an image for a typical neural network(Refered to as a 2-layer network we do not count the input layer as an official). It consists of 3 layers namely:
- Input layer → Inputs to the NN.
- Hidden Layer → Not visible in the training set.
- Output Layer → Responsible for for generating the predicted value .
Computing a Neural Network's Output
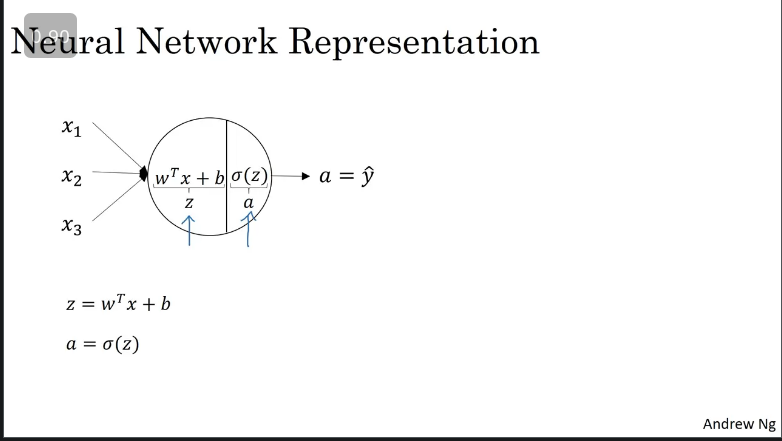
In the previous lessons we were introduced to the computational graph, the circle in the image above represents two steps of computation rows. You initially compute then compute the activation as a sigmoid function of .
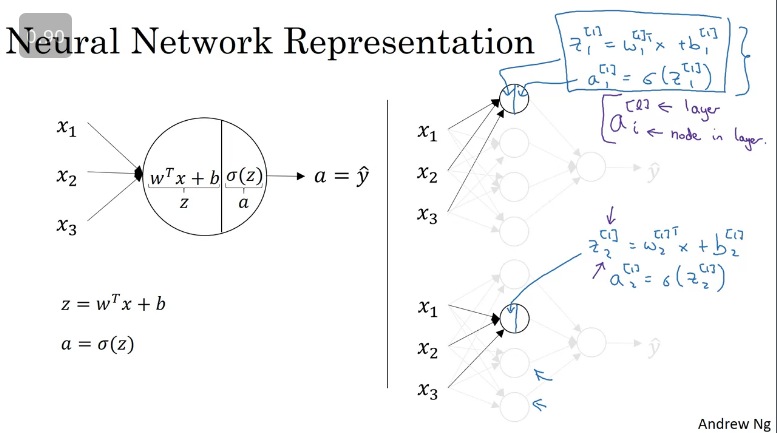
Neural Networks are like logistic regression just theat they repeat a number of times before you get an output as illustrated in the image below. Whereby we compute the logistic regression computation at each node in the neural network in order to get the value of the activation function.
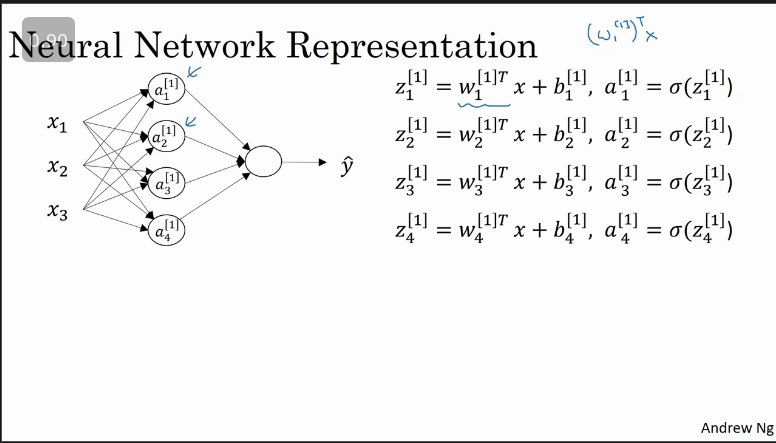
Simplified equations, note that weights are transposed (column vector transpose → row vector := matrix)
Activation functions
When you build a NN, one of the choices you'll be faced with is what activation function do you use for your hidden layers and output layer.
On the previous lessons we used a sigmoid function as an activation functions (Remember: it only outputs the probability)
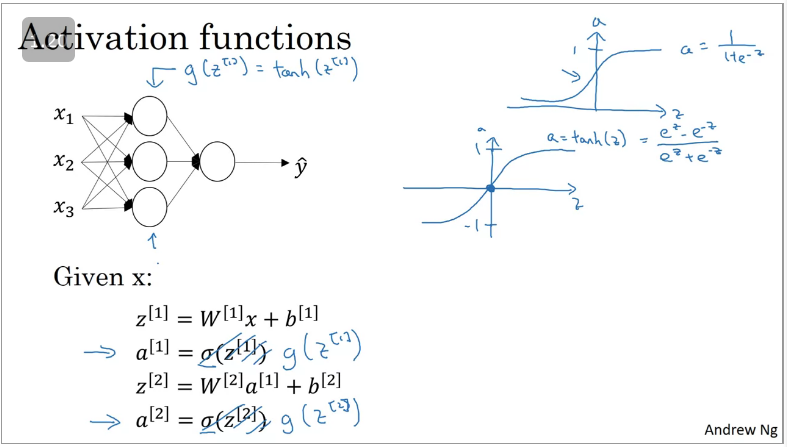
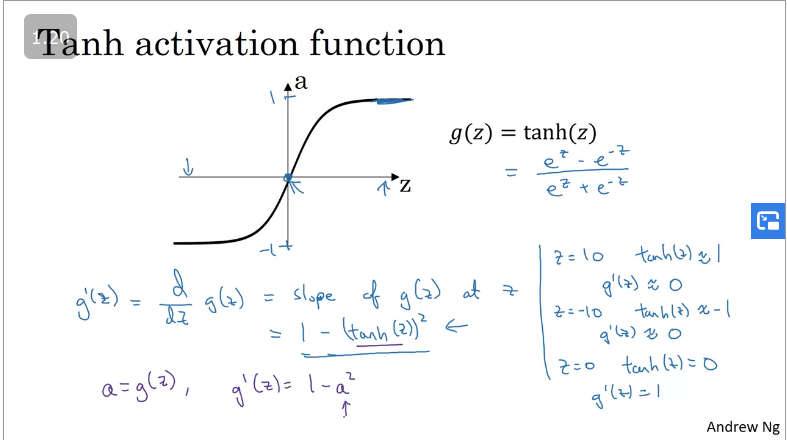
It turns out that if you use the hyperbolic tangent () activation function instead of the sigmoid function, which is a shifted version of the sigmoid function (sigmoid function goes from 1 → 0 where as the latter goes from -1 → +1 which means that the mean is closer to 0).
This makes the learning for the next layer easier as your data is normalised to 0 instead of 0.5 as compared to the sigmoid function.
The hyperbolic tangent activation function is slighly superior than the sigmoid function with an exception for the output layer as your output should be a probability (0→1) for binary classifications as shown in the image below.

Cons:
- If is very large/small, the slope/derivative is small which is close to 0 which can slow down gradient descent.
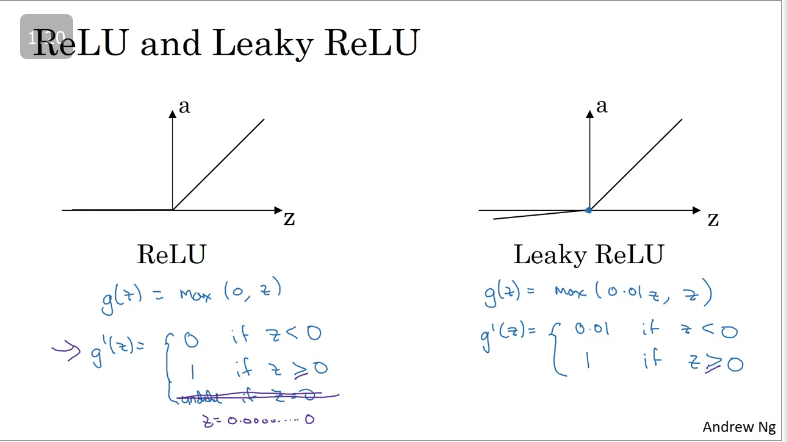
Enter the RELU (Rectify Linear Unit), which is shown in the image below.
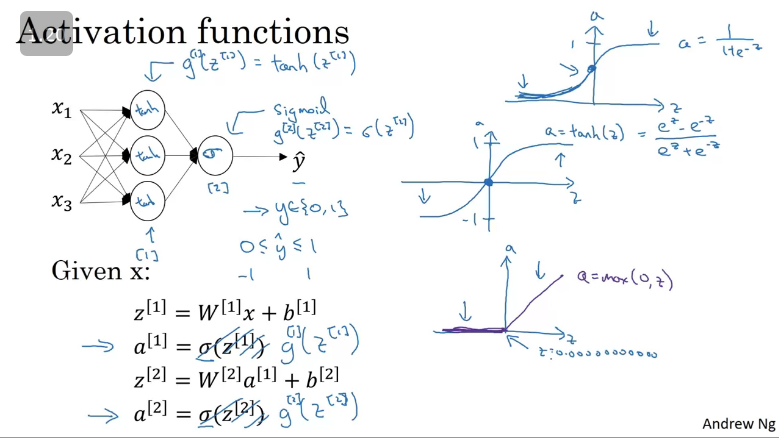
The formular for the RELU function is , such that the derivative is 1 as long as is positive and derivative is 0 when is negative.
Best practices when choosing an activation functions:
- If output is 0/1 or binary classification use → sigmoid function or [Better]
- For everything else use → RELU function
Why do you need non-linear activation functions?
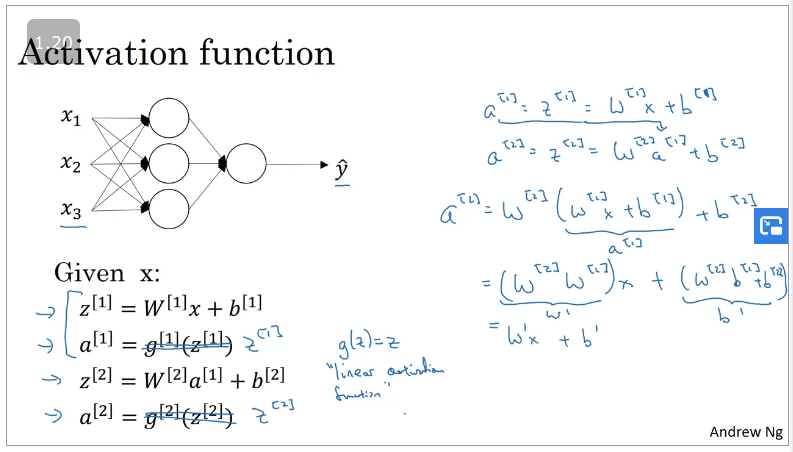
If you were to use linear activation functions (No RELU, sigmoid, tanh activation functions) then the Neural Network will just output/compute a linear activation function which mean there isn't a need for hidden layers.
Linear hidden layer is useless except when you are doing regression problems, an example is estimating house prices as your output wll be a realnumber however the hidden layers need to either be RELU or other activation functions.
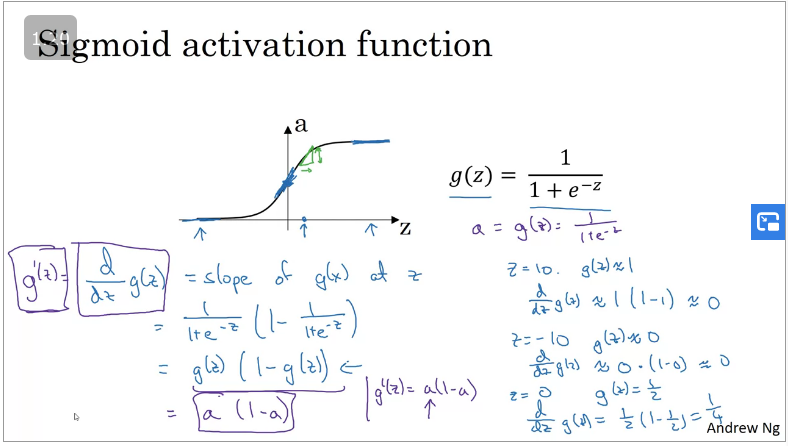
Derivatives of activation functions
When implementing back propagation for a NN you need to compute the slope/derivative of the activation function. Below is a list of activation functions you can choose from.
Sigmoid activation function
Hyperbolic Tangent activation function
RELU activation function
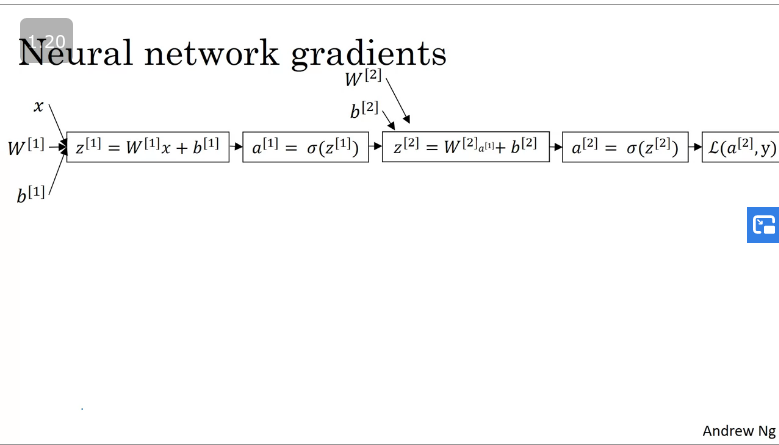
Gradient descent for Neural Networks
Equestions for forward/back propagation

Forward propagation for a neural network computational graph
Back propagation for a neural network computational graph

Cleaner version

Note: equation uses element-wise multiplication.
 https://stackoverflow.com/a/40035266
https://stackoverflow.com/a/40035266
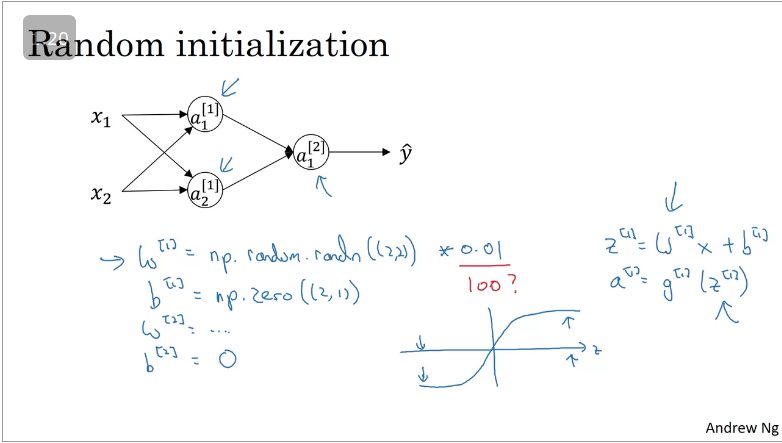
Random Initialization
When training a NN, it is important to initialise the weights randomly, suppose you initalise your weights to zero!
When you compute forward prop: and back prop will be
Thus no matter how many times you train your network the hidden layers units will compute the same exact function i.e there won't be a point for computing the hidden units. This is known as symmetry braking problem
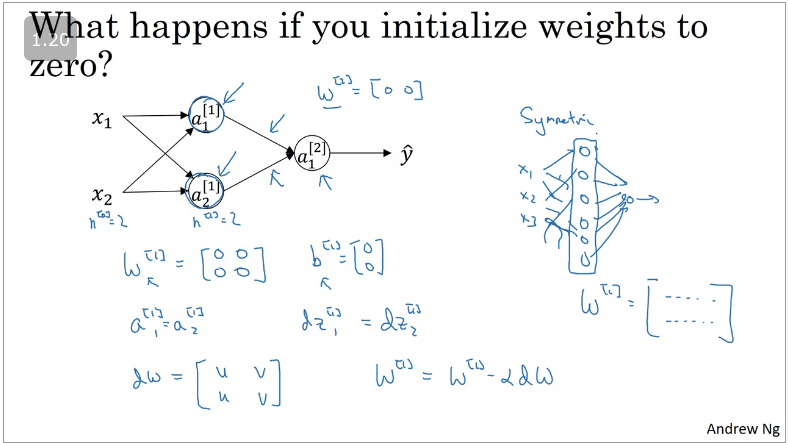
However the case is different when you initialize with randoms weights. It is recommended that you initialize with the smallest weight values as it turns out that if the weight values are very large then your activation function will end up flattening/learning will be slow will be saturated.
Q&A
- Which of the following are true? (Check all that apply.)
- is a matrix in which each column is one training example.
- denotes the activation vector of the 2nd layer for 12th training example.
- denotes the activation vector of the 2nd layer.
- is the activation output by the 4th neuron of the 2nd layer
Correct
- The activation usually works better than sigmoid activation function for hidden units because the mean of its output is closer to zero, and so it centers the data better for the next layer. True
- Yes. As seen in lecture the output of the tanh is between -1 and 1, it thus centers the data which makes the learning simpler for the next layer.
- Which of these is a correct vectorized implementation of forward propagation for layer lll, where?
-
-
- You are building a binary classifier for recognizing cucumbers (y=1) vs.
watermelons (y=0). Which one of these activation functions would you
recommend using for the output layer? sigmoid
- Justification: Yes. Sigmoid outputs a value between 0 and 1 which makes it a very good choice for binary classification. You can classify as 0 if the output is less than 0.5 and classify as 1 if the output is more than 0.5. It can be done with tanh as well but it is less convenient as the output is between -1 and 1.
5. Consider the following code:
A = np.random.randn(4,3) B = np.sum(A, axis = 1, keepdims = True)What will be B.shape? (4, 1)
- Yes, we use (keepdims = True) to make sure that A.shape is (4,1) and not (4, ). It makes our code more rigorous.
6. Suppose you have built a neural network. You decide to initialize the weights and biases to be zero. Which of the following statements is true?
- Each neuron in the first hidden layer will perform the same computation. So even after multiple iterations of gradient descent each neuron in the layer will be computing the same thing as other neurons.
7. Logistic regression’s weights w should be initialized randomly rather than to all zeros, because if you initialize to all zeros, then logistic regression will fail to learn a useful decision boundary because it will fail to “break symmetry”, False
- Justification: Logistic Regression doesn't have a hidden layer. If you initialize the weights to zeros, the first example x fed in the logistic regression will output zero but the derivatives of the Logistic Regression depend on the input x (because there's no hidden layer) which is not zero. So at the second iteration, the weights values follow x's distribution and are different from each other if x is not a constant vector.
8. You have built a network using the tanh activation for all the hidden units. You initialize the weights to relative large values, using np.random.randn(..,..)*1000. What will happen?
- This will cause the inputs of the tanh to also be very large, thus causing gradients to be close to zero. The optimization algorithm will thus become slow.
- Justification: Yes. tanh becomes flat for large values, this leads its gradient to be close to zero. This slows down the optimization algorithm.
9. Consider the following 1 hidden layer neural network:
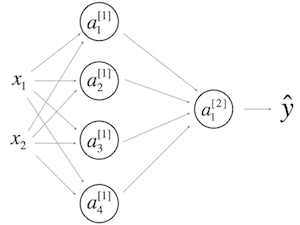
Which of the following statements are True? (Check all that apply).
- will have shape (1, 4)
- will have shape (4, 1)
- will have shape (4, 2)
- will have shape (1, 1)
10. In the same network as the previous question, what are the dimensions of and ?
- and are (4,m)